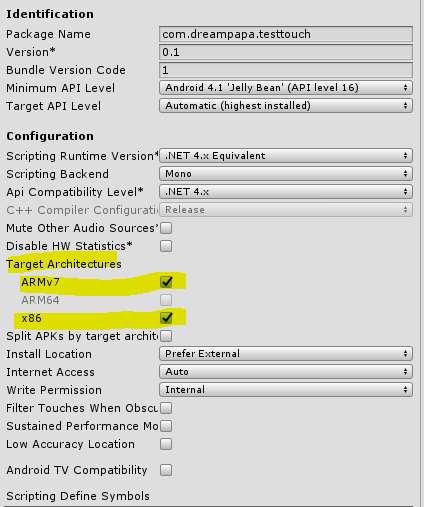
안드로이드 플랫폼 빌드후 기기에 설치 하고 강화 학습을 시도해보았다.
여러경로를 통해 현재는 불가능 하다는것을 알았다.
PC, Mac & Linux Standalone platform으로 빌드를 했다.
다음과 같이 실행파일이 생성되었다.

파일 경로는 다음과 같다.
C:\Users\smilejsu\Desktop\test-mlagent.exe
Anaconda Prompt 를 사용하여 다음 명령어를 통해 훈련을 시도 해보았다.
(base) C:\Users\smilejsu>activate ml-agents
(ml-agents) C:\Users\smilejsu>d:
(ml-agents) D:\>cd D:\workspace\unity\Test\UnitySDK
(ml-agents) D:\workspace\unity\Test\UnitySDK>mlagents-learn trainer_config.yaml --env=C:\Users\smilejsu\Desktop\test-mlagent.exe --run-id=train --train
▄▄▄▓▓▓▓
╓▓▓▓▓▓▓█▓▓▓▓▓
,▄▄▄m▀▀▀' ,▓▓▓▀▓▓▄ ▓▓▓ ▓▓▌
▄▓▓▓▀' ▄▓▓▀ ▓▓▓ ▄▄ ▄▄ ,▄▄ ▄▄▄▄ ,▄▄ ▄▓▓▌▄ ▄▄▄ ,▄▄
▄▓▓▓▀ ▄▓▓▀ ▐▓▓▌ ▓▓▌ ▐▓▓ ▐▓▓▓▀▀▀▓▓▌ ▓▓▓ ▀▓▓▌▀ ^▓▓▌ ╒▓▓▌
▄▓▓▓▓▓▄▄▄▄▄▄▄▄▓▓▓ ▓▀ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▄ ▓▓▌
▀▓▓▓▓▀▀▀▀▀▀▀▀▀▀▓▓▄ ▓▓ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▐▓▓
^█▓▓▓ ▀▓▓▄ ▐▓▓▌ ▓▓▓▓▄▓▓▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▓▄ ▓▓▓▓`
'▀▓▓▓▄ ^▓▓▓ ▓▓▓ └▀▀▀▀ ▀▀ ^▀▀ `▀▀ `▀▀ '▀▀ ▐▓▓▌
▀▀▀▀▓▄▄▄ ▓▓▓▓▓▓, ▓▓▓▓▀
`▀█▓▓▓▓▓▓▓▓▓▌
¬`▀▀▀█▓
INFO:mlagents.trainers:{'--base-port': '5005',
'--curriculum': 'None',
'--debug': False,
'--docker-target-name': 'None',
'--env': 'C:\\Users\\smilejsu\\Desktop\\test-mlagent.exe',
'--help': False,
'--keep-checkpoints': '5',
'--lesson': '0',
'--load': False,
'--no-graphics': False,
'--num-envs': '1',
'--num-runs': '1',
'--run-id': 'train',
'--save-freq': '50000',
'--seed': '-1',
'--slow': False,
'--train': True,
'<trainer-config-path>': 'trainer_config.yaml'}
c:\users\smilejsu\appdata\local\conda\conda\envs\ml-agents\lib\site-packages\mlagents\trainers\learn.py:141: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
trainer_config = yaml.load(data_file)
INFO:mlagents.envs:
'TestAcademy' started successfully!
Unity Academy name: TestAcademy
Number of Brains: 1
Number of Training Brains : 1
Reset Parameters :
Unity brain name: RollerBallBrain
Number of Visual Observations (per agent): 0
Vector Observation space size (per agent): 6
Number of stacked Vector Observation: 1
Vector Action space type: continuous
Vector Action space size (per agent): [2]
Vector Action descriptions: ,
2019-06-05 09:23:09.796920: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
INFO:mlagents.envs:Hyperparameters for the PPO Trainer of brain RollerBallBrain:
batch_size: 10
beta: 0.005
buffer_size: 100
epsilon: 0.2
gamma: 0.99
hidden_units: 128
lambd: 0.95
learning_rate: 0.0003
max_steps: 5.0e4
normalize: False
num_epoch: 3
num_layers: 2
time_horizon: 64
sequence_length: 64
summary_freq: 1000
use_recurrent: False
summary_path: ./summaries/train-0_RollerBallBrain
memory_size: 256
use_curiosity: False
curiosity_strength: 0.01
curiosity_enc_size: 128
model_path: ./models/train-0/RollerBallBrain
c:\users\smilejsu\appdata\local\conda\conda\envs\ml-agents\lib\site-packages\numpy\core\fromnumeric.py:2957: RuntimeWarning: Mean of empty slice.
out=out, **kwargs)
c:\users\smilejsu\appdata\local\conda\conda\envs\ml-agents\lib\site-packages\numpy\core\_methods.py:80: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
INFO:mlagents.trainers: train-0: RollerBallBrain: Step: 1000. Time Elapsed: 8.189 s Mean Reward: -0.976. Std of Reward: 0.623. Training.
INFO:mlagents.trainers: train-0: RollerBallBrain: Step: 2000. Time Elapsed: 15.860 s Mean Reward: -1.394. Std of Reward: 1.200. Training.
INFO:mlagents.trainers: train-0: RollerBallBrain: Step: 3000. Time Elapsed: 23.409 s Mean Reward: -0.484. Std of Reward: 1.027. Training.
INFO:mlagents.trainers: train-0: RollerBallBrain: Step: 4000. Time Elapsed: 30.629 s Mean Reward: -0.551. Std of Reward: 0.405. Training.
INFO:mlagents.trainers: train-0: RollerBallBrain: Step: 5000. Time Elapsed: 37.751 s Mean Reward: -0.378. Std of Reward: 0.480. Training.
다음과 같이 실행파일 (test-mlagent.exe)이 자동으로 실행 되며 훈련이 잘 진행 되었다.

참고:
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Executable.md
Unity-Technologies/ml-agents
Unity Machine Learning Agents Toolkit. Contribute to Unity-Technologies/ml-agents development by creating an account on GitHub.
github.com
https://github.com/Unity-Technologies/ml-agents/issues/2099
How do I train brain after building mobile with ml-agent? · Issue #2099 · Unity-Technologies/ml-agents
Hi. I am a developer who is enjoying ml-agent nowadays. I am trying to follow the documentation here. (https://github.com/Unity-Technologies/ml-agents) I am currently using Windows 10. So I use mla...
github.com
학습이 끝나면 .nn파일도 만들어 졌으며 동적으로 훈련된 모델을 Brain에 넣어 실행 시키는것도 가능했다.
INFO:mlagents.envs:Saved Model
INFO:mlagents.trainers:List of nodes to export for brain :RollerBallBrain
INFO:mlagents.trainers: is_continuous_control
INFO:mlagents.trainers: version_number
INFO:mlagents.trainers: memory_size
INFO:mlagents.trainers: action_output_shape
INFO:mlagents.trainers: action
INFO:mlagents.trainers: action_probs
INFO:mlagents.trainers: value_estimate
INFO:tensorflow:Restoring parameters from ./models/train-0/RollerBallBrain\model-15901.cptk
INFO:tensorflow:Froze 17 variables.
Converted 17 variables to const ops.
Converting ./models/train-0/RollerBallBrain/frozen_graph_def.pb to ./models/train-0/RollerBallBrain.nn
IGNORED: StopGradient unknown layer
GLOBALS: 'is_continuous_control', 'version_number', 'memory_size', 'action_output_shape'
IN: 'vector_observation': [-1, 1, 1, 6] => 'main_graph_0/hidden_0/BiasAdd'
IN: 'vector_observation': [-1, 1, 1, 6] => 'main_graph_1/hidden_0/BiasAdd'
IN: 'epsilon': [-1, 1, 1, 2] => 'mul'
OUT: 'action', 'action_probs', 'value_estimate'
DONE: wrote ./models/train-0/RollerBallBrain.nn file.
INFO:mlagents.trainers:Exported ./models/train-0/RollerBallBrain.nn file
(ml-agents) D:\workspace\unity\Test\UnitySDK>

Android platform 빌드후 기기(안드로이드)에 apk를 설치 하고 앱을 실행시켜 강화 학습을 할수 있는지 궁금하다