

ml-agents v1.0 : Getting Started Guide
Unity3D/ml-agent 2020. 12. 28. 16:24Getting Started Guide
본 가이드는 Unity에서 예제 환경 중 하나를 열고, 에이전트를 교육하고, 교육받은 모델을 Unity 환경에 포함시키는 엔드투엔드 프로세스를 안내합니다. 이 튜토리얼을 읽은 후에는 예제 환경을 교육할 수 있어야 합니다. Unity Engine에 대해 잘 알지 못하는 경우, 당사의 배경을 살펴보십시오. 유용한 포인터의 통합 페이지입니다. 또한, 기계 학습에 익숙하지 않은 경우, 당사의 배경을 살펴보십시오. 간략한 개요와 유용한 포인터에 대한 기계 학습 페이지입니다.

이 가이드를 위해, 우리는 많은 에이전트 큐브와 볼(모두 서로 복사된 것)이 들어 있는 3D 밸런스 볼 환경을 사용할 것이다. 각 에이전트 큐브는 수평 또는 수직으로 회전하여 볼이 떨어지는 것을 막으려고 합니다. 이러한 환경에서 에이전트 큐브는 볼의 균형을 맞추는 모든 단계에 대한 보상을 받는 에이전트입니다. 에이전트는 또한 공을 떨어뜨린 것에 대한 부정적인 보상으로 처벌을 받는다. 훈련 과정의 목표는 요원들이 머리에 공을 균형 있게 하는 법을 배우게 하는 것이다.
시작하자!
Installation
아직하지 않았다면 설치 지침을 따르십시오. 그런 다음 모든 예제 환경이 포함 된 Unity 프로젝트를 엽니다.
Unity Hub 시작 프로젝트 대화 상자의 창 맨 위에 있는 추가 옵션을 선택합니다.
열려 있는 파일 대화 상자를 사용하여 ML-에이전트 툴킷에서 프로젝트 폴더를 찾은 후 열기를 클릭합니다.
프로젝트 창에서 자산/ML-에이전트/예제로 이동하십시오/3DBall/Scene 폴더를 열고 3DBall 장면 파일을 엽니다.
Understanding a Unity Environment
에이전트는 환경을 관찰하고 상호 작용하는 자율적 인 행위자입니다. Unity의 맥락에서 환경은 하나 이상의 Agent 개체와 에이전트가 상호 작용하는 다른 개체를 포함하는 장면입니다.
참고: Unity(유니티)에서 한 장면에 있는 모든 것의 기본 개체는 GameObject(게임 개체)입니다. GameObject는 기본적으로 행동, 그래픽, 물리학 등을 포함한 모든 것을 담는 컨테이너입니다. GameObject를 구성하는 구성 요소를 보려면 Scene 창에서 GameObject를 선택하고 Inspector 창을 엽니다. Inspector는 GameObject의 모든 구성 요소를 표시합니다.
3D Balance Ball 씬(scene)을 연 후 가장 먼저 확인할 수 있는 것은 1개가 아니라 여러 개의 에이전트 큐브를 포함하고 있다는 것입니다. 장면의 각 에이전트 큐브는 독립 에이전트이지만 모두 동일한 동작을 공유합니다. 3D Balance Ball은 12개 에이전트가 모두 병렬로 교육에 기여하기 때문에 훈련 속도를 높이기 위해 이 작업을 수행합니다.
Agent
에이전트는 환경을 관찰하고 행동을 취하는 행위자입니다. 3D Balance Ball 환경에서 에이전트 구성 요소는 12 개의 "에이전트"게임 오브젝트에 배치됩니다. 기본 에이전트 개체에는 동작에 영향을주는 몇 가지 속성이 있습니다.
- Behavior Parameters — 모든 요원은 행동을 취해야 한다. 행동은 요원이 어떻게 결정을 내리는지를 결정한다
- Max Step — 에이전트의 에피소드가 끝나기 전에 발생할 수 있는 시뮬레이션 단계 수를 정의합니다. 3D Balance Ball에서 에이전트는 5000 단계 후에 재시작됩니다.
Behavior Parameters : Vector Observation Space (행동변수 : 벡터 관측공간)
결정을 내리기 전에 에이전트는 세계에서 자신의 상태에 대한 관찰을 수집합니다. 벡터 관찰은 에이전트가 결정을 내리는 데 필요한 관련 정보를 포함하는 부동 소수점 숫자의 벡터입니다.
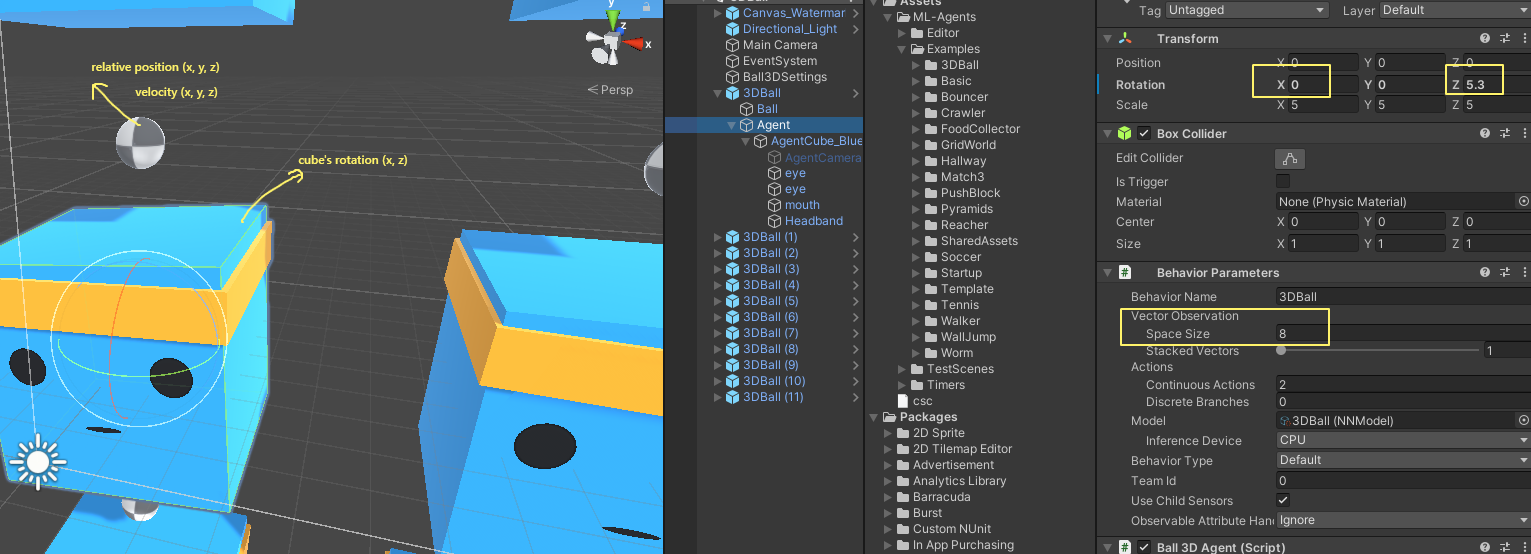
3D Balance Ball 예제의 동작 매개 변수는 8의 공간 크기를 사용합니다. 즉, 에이전트 관측치를 포함하는 형상 벡터에 에이전트 큐브 회전의 x 및 z 성분과 볼의 상대 위치 및 속도의 x, y 및 z 성분 등 8개의 요소가 포함되어 있습니다.
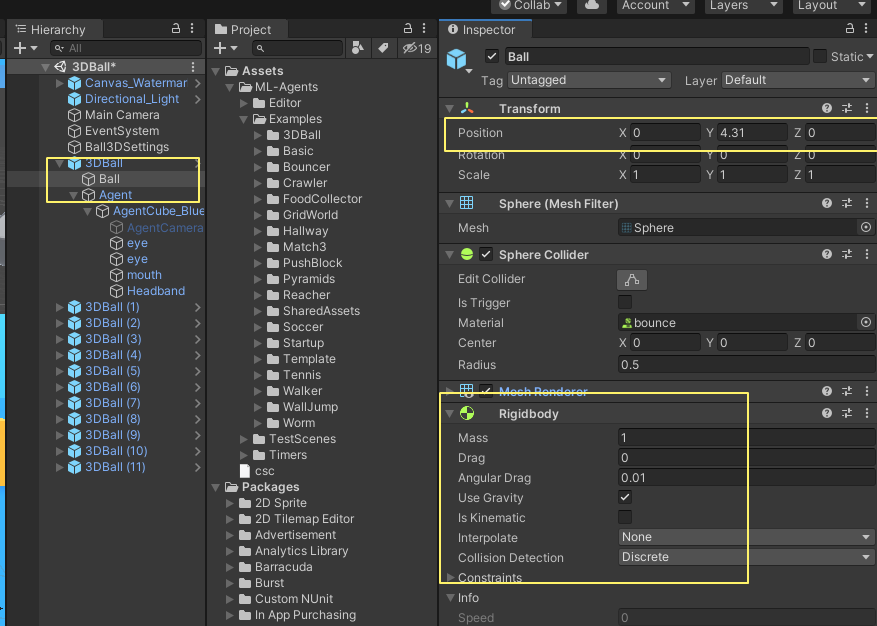
Ball
- Relative Position (local position) : x, y, z
- Velocity : x, y, z
Agent
- cube's rotation : x, z
total : 8

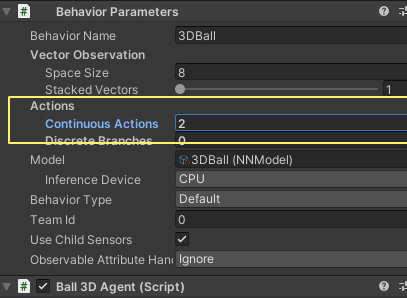
Behavior Parameters : Actions (동작 매개 변수 : 동작)
에이전트에는 작업 형식의 지침이 제공됩니다. ML-에이전트 툴킷은 동작을 연속 및 불연속의 두 가지 유형으로 분류합니다. 3D Balance Ball의 예제는 연속 동작을 사용하도록 프로그래밍되어 있으며, 연속되는 부동 소수점 수의 벡터입니다. 좀 더 구체적으로 말하면, 그것은 공의 균형을 유지하기 위해 머리에 가하기 위해 x와 z 회전의 양을 조절하기 위해 공간 크기를 사용합니다.
Running a pre-trained model
사전 훈련 된 모델 실행
에이전트를위한 사전 훈련 된 모델 (.onnx 파일)을 포함하고 Unity 추론 엔진을 사용하여 Unity 내에서 이러한 모델을 실행합니다. 이 섹션에서는 3D Ball 예제에 대해 사전 학습 된 모델을 사용합니다.
프로젝트 창에서 Assets / ML-Agents / Examples / 3DBall / Prefabs 폴더로 이동합니다. 3DBall을 확장하고 에이전트 프리 팹을 클릭합니다. Inspector 창에 에이전트 프리 팹이 표시되어야합니다.
참고 : 3DBall 장면의 플랫폼은 3DBall 프리 팹을 사용하여 생성되었습니다. 12 개의 플랫폼을 모두 개별적으로 업데이트하는 대신 3DBall 프리 팹을 업데이트 할 수 있습니다.
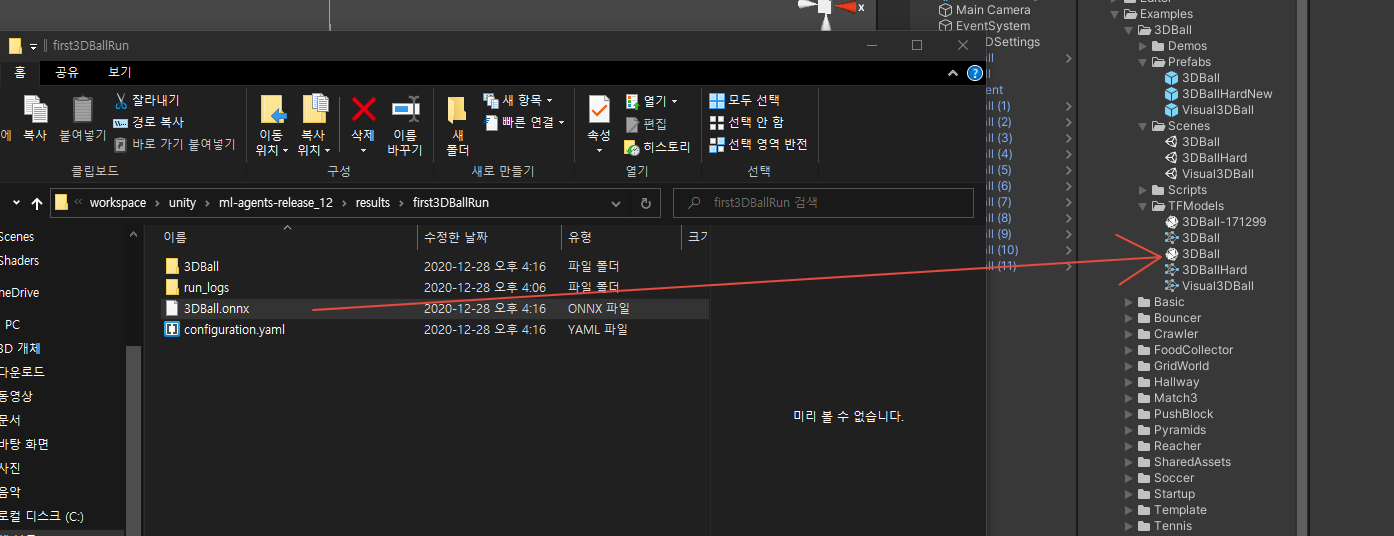
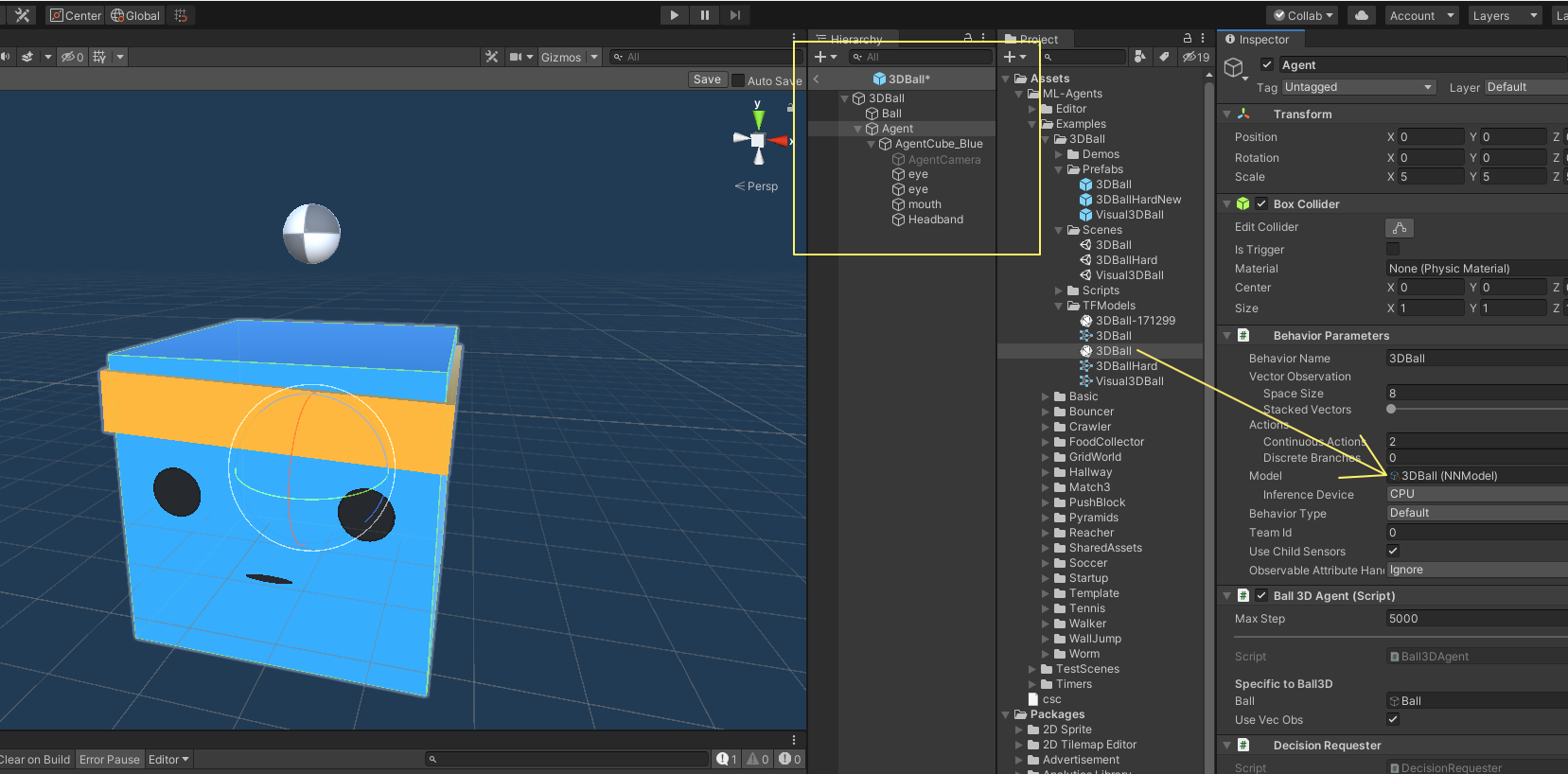
프로젝트 창에서 Assets / ML-Agents / Examples / 3DBall / TFModels에있는 3DBall 모델을 Agent GameObject Inspector 창의 Behavior Parameters (Script) 구성 요소 아래에있는 Model 속성으로 드래그합니다.
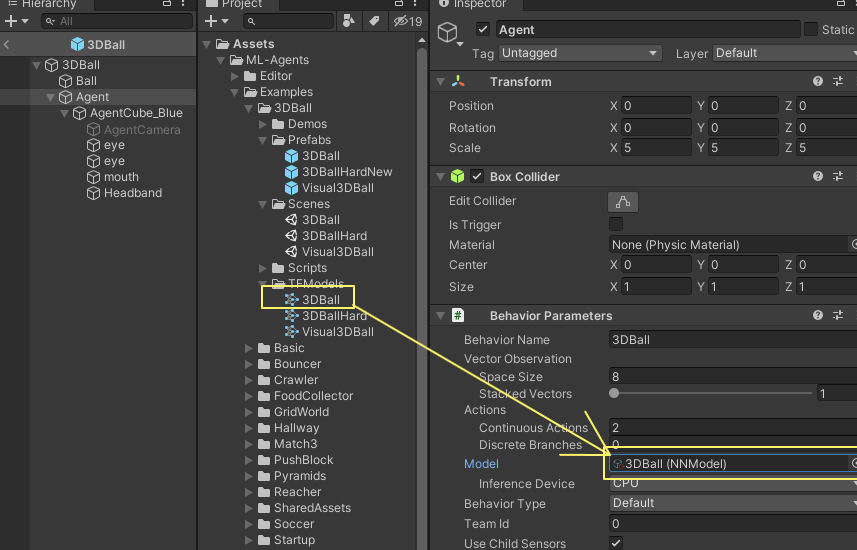
계층 창의 각 3DBall 아래에 있는 각 에이전트가 동작 매개 변수의 모델로 3DBall을 포함합니다. 참고: Scene Hierarchy(장면 계층)의 검색 막대를 사용하여 한 장면에서 여러 게임 개체를 한 번에 선택하여 수정할 수 있습니다.
이 모델에 사용할 추론 장치를 CPU로 설정합니다.
Unity 에디터에서 Play 버튼을 클릭하면 플랫폼이 사전 훈련 된 모델을 사용하여 공의 균형을 맞추는 것을 볼 수 있습니다.
Training a new model with Reinforcement Learning
강화 학습으로 새 모델 훈련
이 환경에서 에이전트에 대해 사전 교육을 받은 모델을 제공하는 동안, 사용자가 직접 만드는 환경은 새로운 모델 파일을 생성하기 위해 처음부터 훈련 에이전트가 필요하다. 이 절에서는 이를 달성하기 위해 ML-Agents Python 패키지의 일부인 강화 학습 알고리즘을 사용하는 방법을 시연할 것이다. 우리는 훈련과 추론 단계를 모두 구성하는 데 사용되는 주장을 수용하는 편리한 명령어 학습을 제공했다.
Training the environment
1. 명령 또는 터미널 창을 엽니다.
2. ml-agents 저장소를 복제 한 폴더로 이동합니다.
참고 : 기본 설치를 따른 경우 모든 디렉토리에서 mlagents-learn을 실행할 수 있습니다.
3. Run mlagents-learn config/ppo/3DBall.yaml --run-id=first3DBallRun
- config/ppo/3DBall.yaml is the path to a default training configuration file that we provide. The config/ppo folder includes training configuration files for all our example environments, including 3DBall.
- run-id is a unique name for this training session.
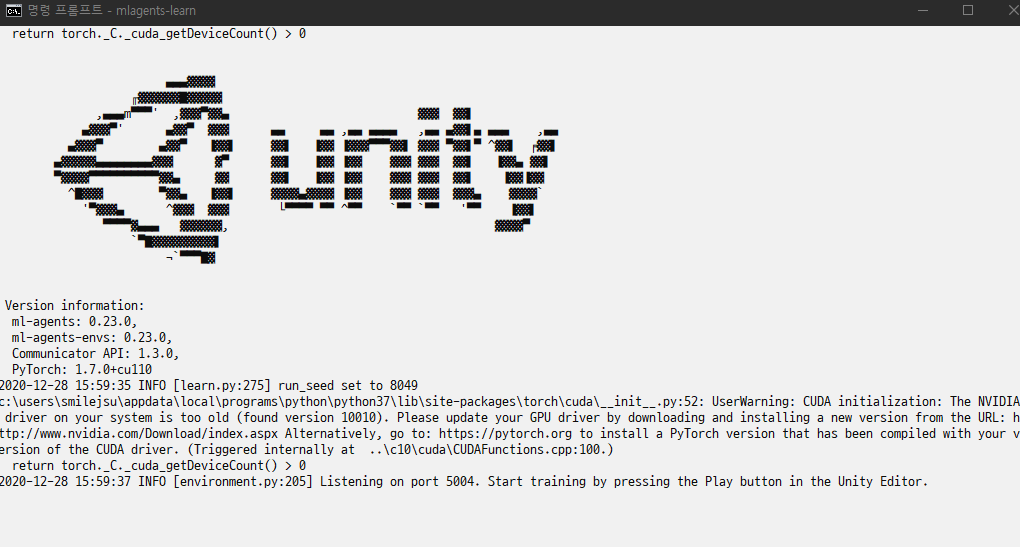
화면에 "Unity Editor에서 Play 버튼을 눌러 훈련 시작"메시지가 표시되면 Unity에서 Play 버튼을 눌러 Editor에서 훈련을 시작할 수 있습니다.
mlagents-learn이 올바르게 실행되고 학습을 시작하면 다음과 같은 내용이 표시됩니다.
2020-12-28 16:02:56 INFO [stats.py:147] Hyperparameters for behavior name 3DBall:
trainer_type: ppo
hyperparameters:
batch_size: 64
buffer_size: 12000
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: True
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory: None
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
init_path: None
keep_checkpoints: 5
checkpoint_interval: 500000
max_steps: 500000
time_horizon: 1000
summary_freq: 12000
threaded: True
self_play: None
behavioral_cloning: None
framework: pytorch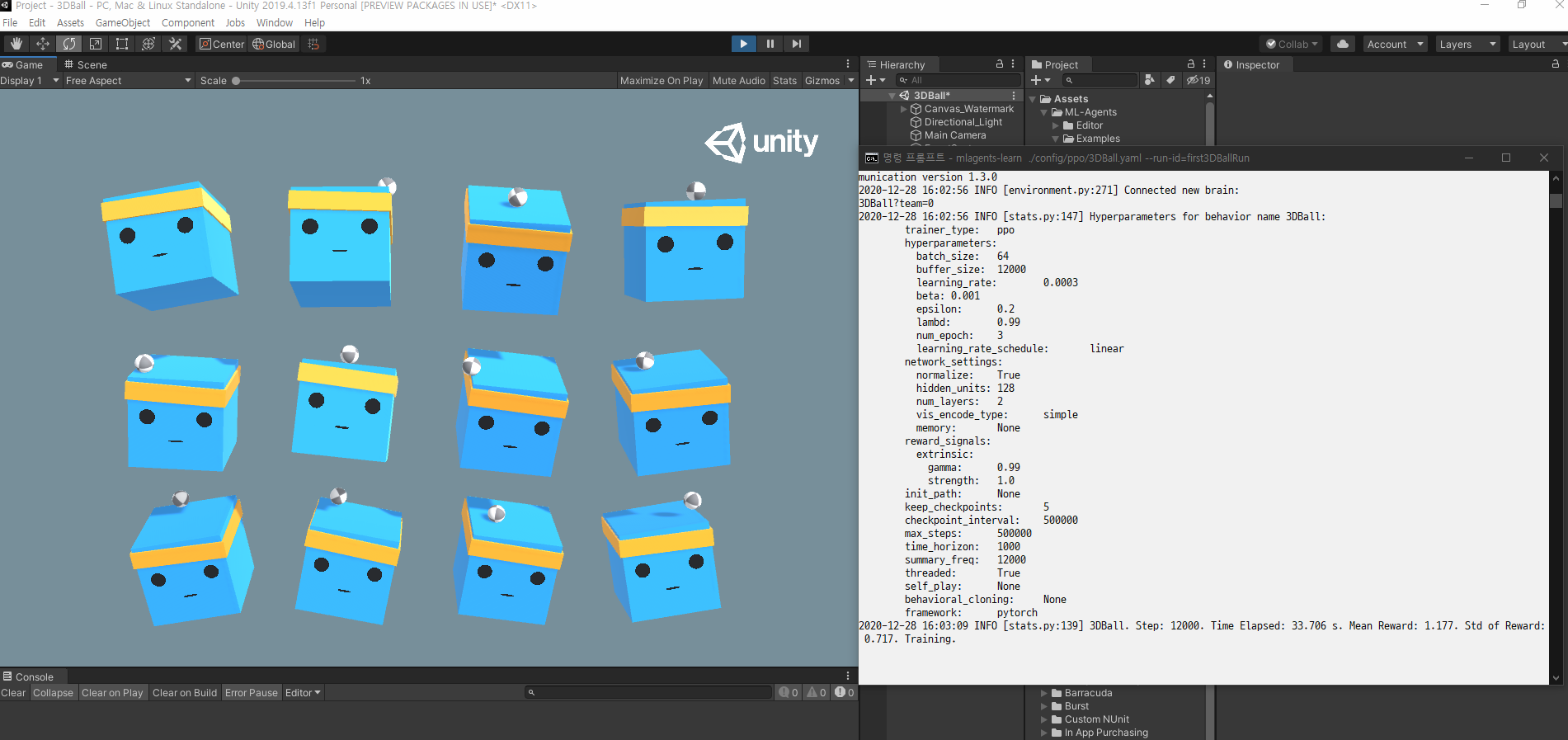
교육이 진행됨에 따라 화면에 출력되는 평균 보상 값이 어떻게 증가하는지 확인합니다. 이것은 훈련이 성공하고 있다는긍정적인 신호이다. 참고: 편집기 대신 실행 파일을 사용하여 교육할 수 있습니다. 이렇게 하려면 실행 파일 사용의 지침을 따릅니다.
Observing Training Progress
훈련 진행 상황 관찰
mlagent를 사용하여 교육을 시작하면 - 이전 섹션에서 설명한 방식으로 학습하면 ml-agents 디렉토리에 결과 디렉토리가 포함됩니다. TensorBoard를 사용하여 교육 과정을 보다 자세히 관찰할 수 있습니다. 명령줄에서 다음을 실행합니다.
tensorboard --logdir results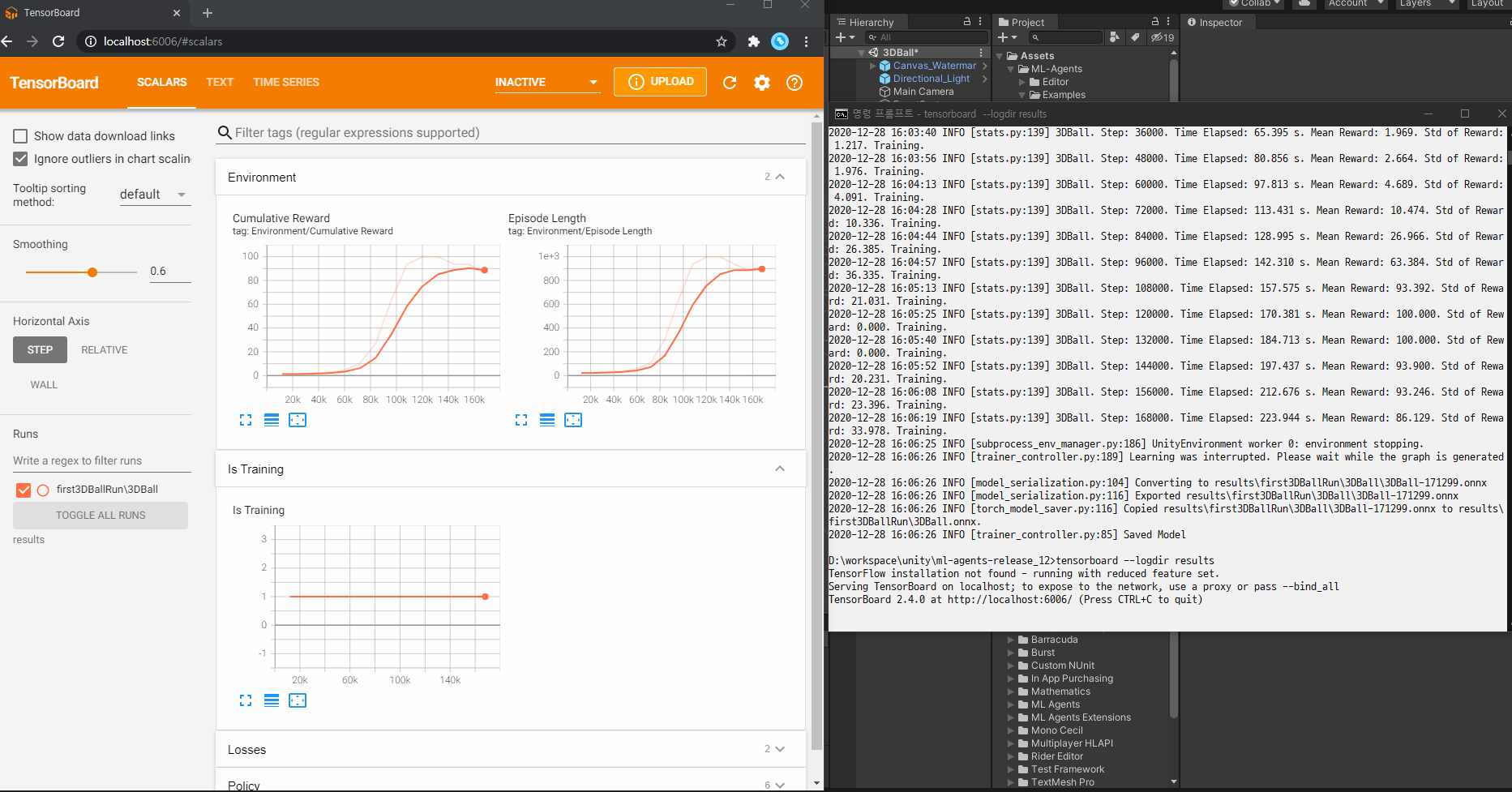
그런 다음 브라우저의 localhost:6006으로 이동하여 아래와 같이 TensorBoard 요약 통계를 봅니다. 본 섹션의 목적을 위해, 가장 중요한 통계는 환경/누적 보상이며, 훈련 내내 증가해야 하며, 결국 대리인이 축적할 수 있는 최대 보상인 100에 가깝게 수렴해야 한다.
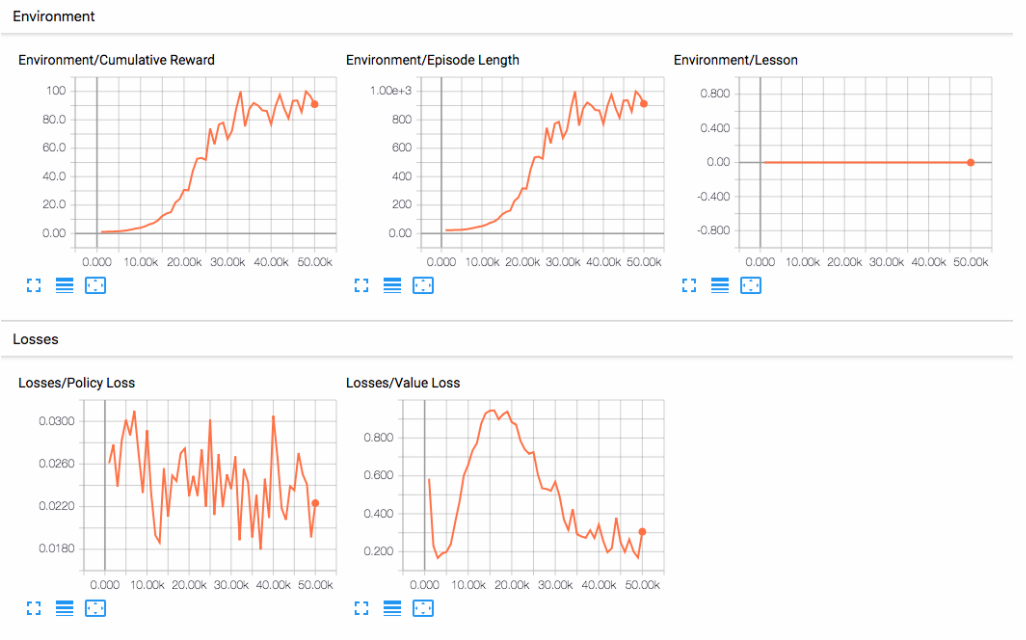
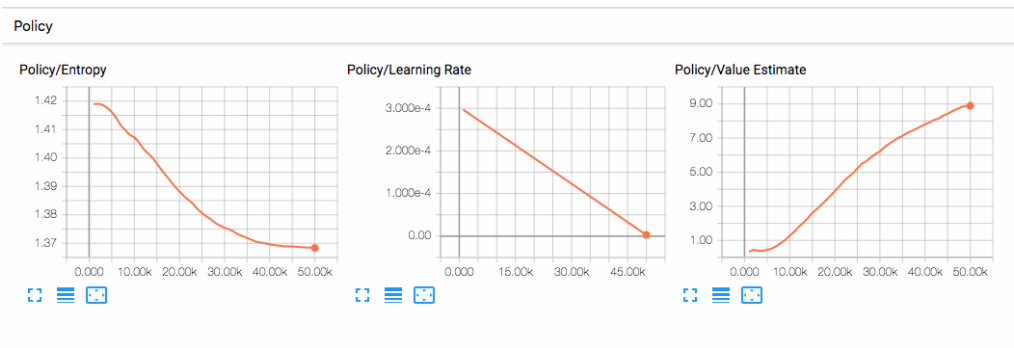
Embedding the model into the Unity Environment
Unity 환경에 모델 임베딩
교육 프로세스가 완료되고 교육 프로세스가 모델을 저장하면(저장된 모델 메시지로 표시됨) 이를 Unity 프로젝트에 추가하여 호환되는 에이전트(모델을 생성한 에이전트)와 함께 사용할 수 있습니다. 참고: 저장된 모델 메시지가 나타나면 Unity 창만 닫지 마십시오. 교육 프로세스가 창을 닫을 때까지 기다리거나 명령줄 프롬프트에서 Ctrl+C를 누릅니다. 창을 수동으로 닫으면 훈련된 모델이 포함된 .onnx 파일이 ml-agent 폴더로 내보내지지 않습니다.
Ctrl+C를 사용하여 교육을 조기에 종료한 경우 교육을 다시 시작하려면 --resume 플래그를 추가하여 동일한 명령을 다시 실행합니다.
mlagents-learn config/ppo/3DBall.yaml --run-id=first3DBallRun --resume학습된 모델은 results/run-identifier/behavior_name.onnx에 있을 것입니다. 여기서 behavior_name은 모델에 해당하는 에이전트의 동작 이름입니다. 이 파일은 모델의 최신 체크포인트에 해당합니다. 이제 위에서 설명한 단계와 유사한 아래 단계를 수행하여 이 교육된 모델을 에이전트에 포함할 수 있습니다.
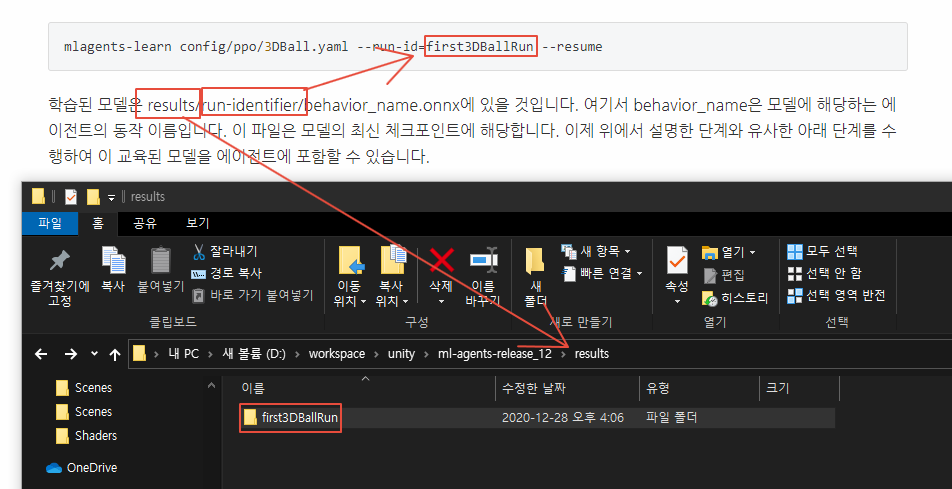
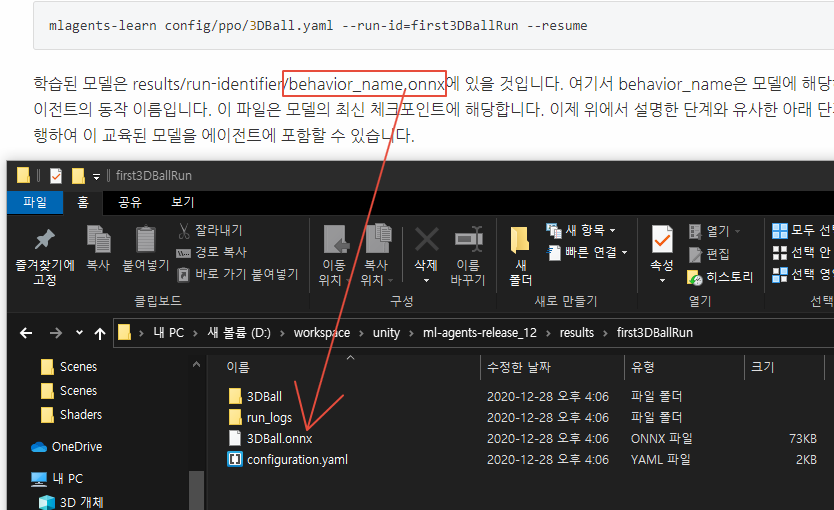
모델 파일을 프로젝트/자산/ML-에이전트/예제로 이동/3DBall/TF 모델/ Unity Editor를 열고 위에서 설명한 대로 3D All 장면을 선택합니다. 3Dall Prefab Agent 개체를 선택합니다. Editor의 Project 창에서 Ball3의 Model 자리 표시자로 <behavience_name.onx> 파일을 드래그합니다.D에이전트 검사 창. 편집기 상단의 재생 버튼을 누릅니다.
Next Steps
ML-Agents Tolkit에 대한 자세한 내용은 도움이 되는 배경 외에도 ML-Agents Tolkit 개요 페이지를 참조하십시오. 여러분만의 학습 환경을 만들기 위한 "안녕 세계" 소개는 새로운 학습 환경 만들기 페이지를 참조하십시오. 이 툴킷에 제공되는 보다 복잡한 예제 환경에 대한 개요는 예제 환경 페이지를 참조하십시오. 사용 가능한 다양한 교육 옵션에 대한 자세한 내용은 교육 ML-Agents 페이지를 참조하십시오.
참고
github.com/Unity-Technologies/ml-agents/blob/release_12_docs/docs/Getting-Started.md
'Unity3D > ml-agent' 카테고리의 다른 글
| Class Academy (0) | 2020.12.28 |
|---|---|
| ml-agents v1.0 : Overview (0) | 2020.12.28 |
| ml-agents v1.0 : Installation (0) | 2020.12.28 |
| ml-agents v1.0 (0) | 2020.12.28 |
| Learn to leverage Artificial Intelligence to enhance your Unity projects (0) | 2020.07.07 |