

[ml-agent] Agents
Unity3D/ml-agent 2019. 5. 28. 22:33Agents
에이전트는 환경을 관찰하고 그러한 관찰을 사용하여 최선의 행동 방침을 결정할 수있는 행위자입니다.
Agent 클래스를 확장하여 Unity에서 에이전트를 생성하십시오.
성공적으로 학습 할 수있는 agent를 만드는 가장 중요한 측면은 에이전트가 강화 학습을 위해 수집 한 관찰 및 agent의 현재 상태 값을 추정하여 작업을 수행하는 데 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
using MLAgents;
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class TestAgent : Agent
{
// Start is called before the first frame update
void Start()
{
}
// Update is called once per frame
void Update()
{
}
}
|
agent는 관찰 내용을 brain에 전달합니다.
brain는 결정을 내리고 선택된 행동을 agent에게 전달합니다.
agent 코드는 agent를 한 방향 또는 다른 방향으로 이동하는 등의 작업을 실행해야합니다.
강화 학습을 하기 위해서 각행동에 따라 보상 값을 계산 해야 합니다.
보상은 최적의 의사 결정 정책을 발견하는 데 사용됩니다.
(보상은 이미 훈련 된 요원이나 모방 학습에 사용되지 않습니다.)
Brain 클래스는 의사 결정 로직을 에이전트 자체에서 추상화하므로 여러 에이전트에서 동일한 Brain을 사용할 수 있습니다.
두뇌가 그 결정을 내리는 방법은 두뇌의 종류에 달려 있습니다.
Player Brain을 사용하면 상담원을 직접 제어 할 수 있습니다.
경험적 브레인 (Behuristic Brain)을 사용하면 의사 결정 스크립트를 작성하여 일련의 규칙으로 에이전트를 제어 할 수 있습니다.
Behuristic Brain: 직접 코딩한 동작을 기반으로 행동을 결정합니다.
https://blogs.unity3d.com/kr/2017/09/19/introducing-unity-machine-learning-agents/
이 두뇌는 신경 네트워크를 포함하지 않지만 디버깅에 유용 할 수 있습니다.
Learning Brain을 사용하면 agent를 위한 신경망 모델을 학습하고 사용할 수 있습니다.
Brain을 참조하십시오.
Decisions
관측 - 결정 - 행동 - 보상주기는 구성 가능한 수의 시뮬레이션 단계 (주파수는 기본적으로 1 단계 당 1 단계) 이후에 반복됩니다.
또한 요청에 따라 결정을 요청할 수 있도록 에이전트를 설정할 수 있습니다.
정기적인 간격으로 의사 결정을하는 것이 일반적으로 물리 기반 시뮬레이션에 가장 적합합니다.
수요에 대한 의사 결정은 일반적으로 상담원이 특정 이벤트에만 응답하거나 다양한 기간 동안 조치를 취하는 상황에 적절합니다.
예를 들어, 로봇 시뮬레이터의 에이전트는 조인트 토크의 정밀 제어를 제공해야 시뮬레이션의 모든 단계를 결정해야합니다.
반면에 특정 게임이나 시뮬레이션 이벤트가 발생할 때만 의사 결정을 수행해야하는 에이전트는 주문형 의사 결정(on-demand decision making)을 사용해야합니다.

단계 기반 의사 결정의 빈도를 제어하려면 Unity Inspector 창에서 상담원 객체의 의사 결정 빈도 값(Decision Frequency value)을 설정하십시오.
일단 인스펙터에 안보임...
Decision Frequency value 이건가

툴팁: 에이전트는 모든 X 단계마다 자동으로 결정을 요청하고 모든 단계에서 조치를 수행합니다
동일한 Brain 인스턴스를 사용하는 상담원은 다른 빈도를 사용할 수 있습니다. 의사 결정이 요청되지 않은 시뮬레이션 단계 중에 에이전트는 이전 결정에 의해 선택된 것과 동일한 조치를받습니다.
On Demand Decision Making
On demand decision making을 통해 상담원은 고정 주파수로 결정을받는 대신 필요시에만 의사의 결정을 요청할 수 있습니다.
이는 에이전트가 다양한 단계 수에 대한 조치를 수행하거나 에이전트가 동시에 의사 결정을 할 수없는 경우에 유용합니다.
이것은 일반적으로 턴 기반 게임의 경우이며, 에이전트가 이벤트 또는 게임에 반응해야하는 게임 인 경우 에이전트는 다양한 기간 동안 행동을 취할 수 있습니다.
에이전트에 대한 On Demand Decisions를 설정하면 에이전트 코드에서 Agent.RequestDecision () 함수를 호출해야합니다.
에이전트가 새로운 결정을 위해 두뇌를 요청해야 할 때 호출됩니다.
|
1
2
3
4
5
6
7
8
|
/// <summary>
/// Is called when the agent must request the brain for a new decision.
/// </summary>
public void RequestDecision()
{
requestDecision = true;
RequestAction();
}
|
|
1
2
3
4
5
6
7
8
9
10
|
using MLAgents;
public class TestAgent : Agent
{
void Start()
{
this.RequestDecision();
}
}
|
이 함수 호출은 관찰 - 결정 - 행동 - 보상주기의 한 반복을 시작합니다.
Brain은 Agent의 CollectObservations () 메소드를 호출하고 결정을 내리고 AgentAction () 메소드를 호출하여이를 리턴합니다.
브레인은 다른 반복을 시작하기 전에 에이전트가 다음 결정을 요청할 때까지 기다립니다.
결정을 내리기 위해 에이전트는 세계의 상태를 추론하기 위해 환경을 관찰해야합니다. 주 관측은 다음과 같은 형태를 취할 수 있습니다 :
Vector Observation (벡터 관측) - 부동 소수점 수 배열로 구성된 피쳐 벡터입니다.
Visual Observations - 하나 이상의 카메라 이미지 및 / 또는 텍스처 렌더링.
에이전트에 대해 벡터 관측을 사용하는 경우 Agent.CollectObservations () 메서드를 구현하여 특징 벡터를 만듭니다.
Visual Observations를 사용할 때 Unity Camera 객체 또는 RenderTexture가 이미지를 제공하고 기본 Agent 클래스가 나머지를 처리하는지 확인하기 만하면됩니다.
이 함수를 구현하면 AddVectorObs를 호출하여 벡터 관측치를 추가해야합니다.
agent가 시각 관측(visual observations)을 사용하는 경우 (벡터 관측을 사용하지 않는 경우) CollectObservations () 메소드를 구현할 필요가 없습니다.
Vector Observation Space: Feature Vectors
연속 상태 공간을 사용하는 agent 경우 시뮬레이션의 각 단계에서 상담원의 관찰을 나타내는 피쳐 벡터를 생성합니다.
연속 상태 공간(a continuous state space)?
이런 공간을 의미 하는건가?

Brain 클래스는 각 에이전트의 CollectObservations () 메소드를 호출합니다.
이 함수를 구현하면 AddVectorObs를 호출하여 벡터 관측치(vector observations)를 추가해야합니다.
관찰에는 에이전트가 작업을 수행하는 데 필요한 모든 정보가 포함되어야합니다.
충분하고 적절한 정보가 없으면 agent가 제대로 학습하지 못하거나 전혀 배우지 못할 수도 있습니다.
어떤 정보가 포함되어야하는지 결정하기위한 합리적인 접근법은 문제에 대한 분석적 솔루션을 계산하는 데 필요한 것이 무엇인지 고려하는 것입니다.
다양한 상태 관측 기능의 예를 보려면 ML-Agents SDK에 포함 된 예제 환경을 살펴보십시오.
예를 들어, 3DBall 예제는 플랫폼의 회전, 볼의 상대 위치 및 볼의 속도를 상태 관찰로 사용합니다.
실험으로 관측에서 속도 성분을 제거하고 3DBall 에이전트를 재교육 할 수 있습니다.
합리적으로 공의 균형을 잡는것을 해우겠지만 속도를 사용하지 않는 agent의 선능은 현저하게 악화 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public GameObject ball;
private List<float> state = new List<float>();
public override void CollectObservations()
{
AddVectorObs(gameObject.transform.rotation.z);
AddVectorObs(gameObject.transform.rotation.x);
AddVectorObs((ball.transform.position.x - gameObject.transform.position.x));
AddVectorObs((ball.transform.position.y - gameObject.transform.position.y));
AddVectorObs((ball.transform.position.z - gameObject.transform.position.z));
AddVectorObs(ball.transform.GetComponent<Rigidbody>().velocity.x);
AddVectorObs(ball.transform.GetComponent<Rigidbody>().velocity.y);
AddVectorObs(ball.transform.GetComponent<Rigidbody>().velocity.z);
}
|
특징 벡터는 항상 같은 수의 요소를 포함해야하며 관측치는 항상 목록 내의 동일한 위치에 있어야합니다.
환경에서 관찰 된 엔티티 수가 다를 수있는 경우 특정 관찰에서 누락 된 엔티티에 대해 특성 벡터를 0으로 채우거나 에이전트의 관측치를 고정 된 하위 집합으로 제한 할 수 있습니다.
예를들어 한 환경에서 모든 적의 에이전트를관찰하는 대신, 가장 가까운 다섯개만 관찰 할수 있다.
Unity Editor에서 Agent 's Brain을 설정하는 경우 연속 벡터 관찰을 사용하도록 다음 속성을 설정하십시오.
공간 크기 - 상태 크기는 특성 벡터의 길이와 일치해야합니다.
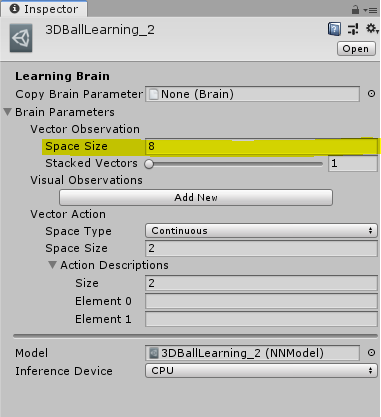
관찰 특징 벡터는 부동 소수점 숫자의 목록입니다.
즉, 다른 데이터 유형을 부동 소수점 또는 부동 소수점 목록으로 변환해야합니다.
<요약>
에이전트 관찰은 에이전트의 관점에서 현재 환경을 설명합니다.
<비고>
간단히 말해서 상담원 관측은 상담원이 목표를 달성하는 데 도움이되는 모든 환경 정보입니다.
예를 들어, 전투 요원의 경우, 그 관찰은 친구 나 적과의 거리, 또는 처분 할 수있는 탄약의 현재 수준을 포함 할 수 있습니다.
에이전트는 벡터, 시각 또는 텍스트 관찰을 첨부 할 수 있습니다.
벡터 관측치는 제공된 헬퍼 메소드를 호출하여 추가됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
/// <summary>
/// Collects the (vector, visual, text) observations of the agent.
/// The agent observation describes the current environment from the
/// perspective of the agent.
/// </summary>
/// <remarks>
/// Simply, an agents observation is any environment information that helps
/// the Agent acheive its goal. For example, for a fighting Agent, its
/// observation could include distances to friends or enemies, or the
/// current level of ammunition at its disposal.
/// Recall that an Agent may attach vector, visual or textual observations.
/// Vector observations are added by calling the provided helper methods:
/// - <see cref="AddVectorObs(int)"/>
/// - <see cref="AddVectorObs(float)"/>
/// - <see cref="AddVectorObs(Vector3)"/>
/// - <see cref="AddVectorObs(Vector2)"/>
/// - <see cref="AddVectorObs(float[])"/>
/// - <see cref="AddVectorObs(List{float})"/>
/// - <see cref="AddVectorObs(Quaternion)"/>
/// - <see cref="AddVectorObs(bool)"/>
/// - <see cref="AddVectorObs(int, int)"/>
/// Depending on your environment, any combination of these helpers can
/// be used. They just need to be used in the exact same order each time
/// this method is called and the resulting size of the vector observation
/// needs to match the vectorObservationSize attribute of the linked Brain.
/// Visual observations are implicitly added from the cameras attached to
/// the Agent.
/// Lastly, textual observations are added using
/// <see cref="SetTextObs(string)"/>.
/// </remarks>
|
환경에 따라 이러한 헬퍼의 조합을 사용할 수 있습니다.
이 메소드가 호출 될 때마다 정확히 동일한 순서로 사용하면되고 벡터 결과의 결과 크기는 링크 된 Brain의 vectorObservationSize 속성과 일치해야합니다.
시각적 관찰은 에이전트에 연결된 카메라에서 암시 적으로 추가됩니다.
마지막으로 텍스트 관찰은 다음을 사용하여 추가됩니다.
Integer와 boolean을 관찰 벡터에 직접 추가 할 수있을뿐 아니라 Vector2, Vector3, Quaternion과 같은 일반적인 Unity 데이터 유형을 추가 할 수 있습니다.
형식 열거 형은 one-hot 스타일로 인코딩되어야합니다.
즉, 열거의 각 요소에 대해 특성 벡터에 요소를 추가하고 관찰 된 구성원을 나타내는 요소를 1로 설정하고 나머지는 0으로 설정합니다.
예를 들어 열거 형에 [Sword, Shield, Bow]가 포함되어 있고 Bow를 관찰 하고 싶을 경우 0, 0, 1 요소를 특징 벡터에 추가 한다.
다음 예제에서는 어떻게 추가하는지 설명한다.
|
1
2
3
4
5
6
7
8
9
|
enum CarriedItems { Sword, Shield, Bow, LastItem }
private List<float> state = new List<float>();
public override void CollectObservations()
{
for (int ci = 0; ci < (int)CarriedItems.LastItem; ci++)
{
AddVectorObs((int)currentItem == ci ? 1.0f : 0.0f);
}
}
|
AddVectorObs 는 2개의 인자를 가지고있는 버전또한 제공한다.
다음 예제는 이전예제와 동일 하다
|
1
2
3
4
5
6
7
8
9
|
enum CarriedItems { Sword, Shield, Bow, LastItem }
const int NUM_ITEM_TYPES = (int)CarriedItems.LastItem;
public override void CollectObservations()
{
// The first argument is the selection index; the second is the
// number of possibilities
AddVectorObs((int)currentItem, NUM_ITEM_TYPES);
}
|
첫 번째 인수는 선택 색인입니다. 두 번째는 가능성의 수이다.
(원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다. 이렇게 표현된 벡터를 원-핫 벡터(One-hot vector)라고 합니다.)
참조: https://wikidocs.net/22647
Normalization
학습 할 때 최상의 결과를 얻으려면, 특징 벡터의 구성 요소를 [-1, +1] 또는 [0, 1] 범위로 정규화해야합니다.
값을 정규화하면 PPO 신경망이 더 빠르게 솔루션으로 수렴 될 수 있습니다.
이 권장 범위로 정규화 할 필요는 없지만 신경망을 사용할때 모범 사례로 간주 된다.
관측 구성요소간의 범위 편차가 클수록 교육에 영향을 줄 가능성이 커진다.
값을 [0, 1]로 정규화하려면 다음 공식을 사용할 수 있습니다.
normalizedValue = (currentValue - minValue)/(maxValue - minValue)
회전 및 각도도 표준화 해야 한다.
0 ~ 360도 사이의 각도의 경우 다음 수식을 사용 할수 있다.
Quaternion rotation = transform.rotation;
Vector3 normalized = rotation.eulerAngles / 180.0f - Vector3.one; // [-1,1]
Vector3 normalized = rotation.eulerAngles / 360.0f; // [0,1]0 ~ 350범위를 벗어날수 있는 각도의 경우 각도를 줄이거나 회전수가 중요하면 정규화 공식에 사용된 최대값을 늘리십시오
Multiple Visual Observations
시각적 관찰은 렌더링 된 텍스쳐를 직접 사용하거나 장면의 하나 이상의 카메라에서 사용한다.
Brain은 텍스쳐를 3D Tensor로 벡터화 하여 convolutional neural network에 입력 할수 있다.
CNN에 대한 자세한 내용은이 가이드를 참조하십시오. 측면 벡터 관측과 함께 시각적 관측을 사용할 수 있습니다.
... 이하 생략 아직 시각적 관찰은 나에게 필요하지 않으므로
Vector Actions
액션이란 Agent가 수행하는 Brain의 지시임.
Academy가 Agent의 Agentaction() 메서드를 호출할때 작업이 매개변수로 Agent에게 전달됨.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
/// <summary>
/// Specifies the agent behavior at every step based on the provided
/// action.
/// </summary>
/// <param name="vectorAction">
/// Vector action. Note that for discrete actions, the provided array
/// will be of length 1.
/// </param>
/// <param name="textAction">Text action.</param>
public virtual void AgentAction(float[] vectorAction, string textAction)
{
}
|
vector action space 를 Continuous로 지정하면 action parameter 가 Agent로 전달 된다.
전달된 매개변수는 Vector Action Space Size속성과 길이가 동일한 제어 신호 배열이다.
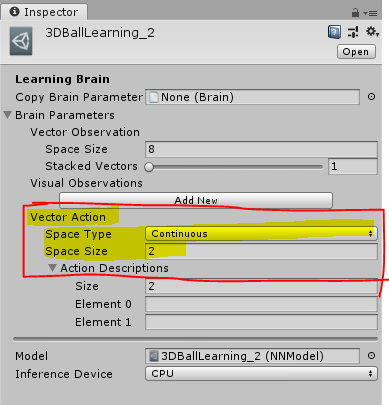

Discrete Vector로 지정하면 매개변수는 정수배열이다.
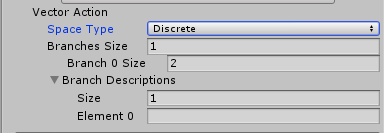
각정수는 목록또는 명령 표에 대한 Index다.
Discrete Vector에서 Action Parameter는 인덱스 배열이다.
배열의 인덱스 수는 Branches Size 속성에 정의 된 분기 수에 의해 결정된다.
Branches Size : 각 분기는 작업 테이블에 해당하며 분기 속성을 수정하여 각 테이블의 크기를 지정할수 있다.
Branch Descriptions : 분기 설명 속성은 사용가능한 각 분기 이름을 포함한다.
Unity Editor Inspector 창을 사용하여 에이전트에 할당 된 Brain 객체에 Vector Action Space Size 및 Vector Action Space Type 속성을 설정하십시오.
Brain이나 training 알고리즘은 액션 값 자체가 의미하는 바를 전혀 모른다.
훈련 알고리즘은 단순히 행동 목록에 대해 다른 값을 시도 하고 시간이 지남에 따라 누적된 보상 및 많은 훈련 에피소드에 대한 영향을 관찰 한다.
따라서 Agent에 대해 AgentAction() 함수에 있는 유일한 작업을 정의한다.
단순히 벡터 작업 공간의 유형을 지정하고 연속 벡터 작업 공간의 경우 값 수를 입력 한 다음 ActionAct ()에서 적절히 (그리고 일관되게)받은 값을 적용하면됩니다.
예를들어 Agent를 2차원으로 이동하도록 설계한후 연속 또는 개별 벡터 동작을 사용할수 있다.
연속적인 경우 vector action size를 2로 설정하고 Agent의 Brain은 두개의 부동 소수점 값이 있는 작업을 만들면 된다.
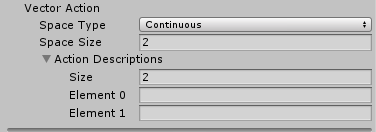
discrete 일경우 Branch 사이즈를 4개로 설정한다.
Brain은 0 ~ 3까지값을 갖는 단일 요소를 포함하는 동작 배열을 만들거다.
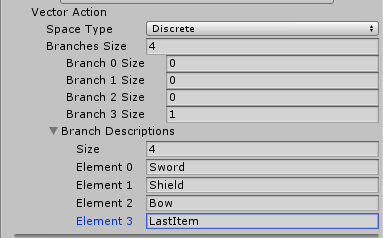
둘중하나로 2개의 Branch를 만들수 있다.
하나는 수평 이동
하나는 수직 이동
Brain은 0 ~ 1까지의 값을 갖는 두개의 요소를 포함하는 동작 배열을 만든다.
Agent에 대한 액션을 프로그래밍 할 때 키보드 커맨드를 액션에 매핑할수 있는 플레이어 브레인 (Player Brain)을 사용하여 액션 로직을 테스트 하는것이 좋다.
자세한내용은 Brains을 참고 하자
The 3DBall 및 Area 예제 환경은 Continuous 또는 Discrete Vector 액션을 사용하도록 설정 되어 있다.
Continuous Action Space
Agent가 Continuous 로 설정된 Brain을 사용할 경우 Agent의 AgentAction()함수에 전달된 action 매개변수는 Brain객체의 벡터 동작 공간 크기 속성값과 같은 길이의 배열이다.
배열의 개별 값에는 사용자가 정한 의미와 관계가 있다.
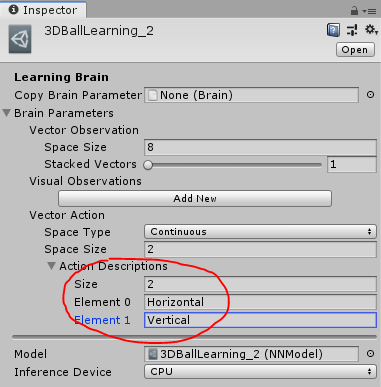
Agent의 속도를 배열의 요소에 할당 하는 경우
훈련 과정은 매배변수를 통해 Agent의 속도를 제어 하는것을 배울것이다.
Reacher example는 4 개의 제어 값을 갖는 연속 동작 공간을 정의합니다.
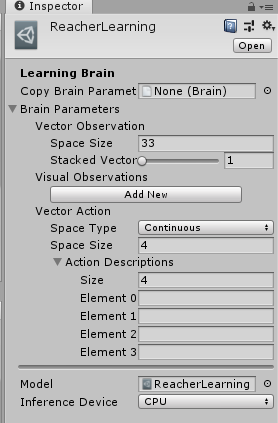
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
/// <summary>
/// The agent's four actions correspond to torques on each of the two joints.
/// </summary>
public override void AgentAction(float[] vectorAction, string textAction)
{
goalDegree += goalSpeed;
UpdateGoalPosition();
rbA.AddTorque(new Vector3(torqueX, 0f, torqueZ));
rbB.AddTorque(new Vector3(torqueX, 0f, torqueZ));
}
|
이 제어 값은 팔을 구성하는 몸체에 적용되는 토크입니다.
기본적으로 제공된 PPO 알고리즘의 출력은 vectorAction의 값을 [-1, 1] 범위로 미리 클램프합니다.
https://openai.com/blog/openai-baselines-ppo/
Proximal Policy Optimization
We’re releasing a new class of reinforcement learning algorithms, Proximal Policy Optimization (PPO), which perform comparably or better than state-of-the-art approaches while being much simpler to implement and tune.
openai.com
사용자 환경에서 타사 알고리즘을 사용하려는 경우 수동으로 클립핑 하는것이 좋다.
위에서 표시된것 처럼 컨트롤 값을 클램프 한 후 필요에 따라 컨트롤 값을 스케일 할 수 있다.
Discrete Action Space
Agent 가 discrete vector action space로 설저된 Brain을 사용할 경우 action 매개변수는 Agent의 AgentAction()메서드는 인덱스가 포함된 배열을 가진다.
Discrete Vector action space에서 Branches는 정수 배열이며 각 값은 각 분기의 가능성 수에 해당한다.
예를들어 비행기에 움직이고 점프 할수 있는 Agent를 원한다면 두개의 지점을 정의 할수 있다(모션용, 점프용)
Agent는 동시에 움직이고 점프 할수 있기를 원하기 때문이다.
우리는 첫번째 Branch를 5가지 가능한 행동으로 정의한다
1. 움직이지 않기
2. 왼쪽으로 가기
3. 오른쪽으로 가기
4. 뒤로가기
5. 앞으로 나아가기
두번째 행동은 2가지 행동을 취할수 있다.(점프 하거나 점프하지 말것)
AgentAction메서드는 다음과 같다
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// Get the action index for movement
int movement = Mathf.FloorToInt(act[0]);
// Get the action index for jumping
int jump = Mathf.FloorToInt(act[1]);
// Look up the index in the movement action list:
if (movement == 1) { directionX = -1; }
if (movement == 2) { directionX = 1; }
if (movement == 3) { directionZ = -1; }
if (movement == 4) { directionZ = 1; }
// Look up the index in the jump action list:
if (jump == 1 && IsGrounded()) { directionY = 1; }
// Apply the action results to move the Agent
gameObject.GetComponent<Rigidbody>().AddForce(
new Vector3(
directionX * 40f, directionY * 300f, directionZ * 40f));
|
위 코드 예제는 AreaAgent클래스의 단순 추출물로, 이산 액션 공간과 연속 동작 공간에 대한 대체 구현을 제공한다.
Masking Discrete Actions(불연속 액션 마스킹 )
이산 행동을 사용할때 다음 결정을 위해 불가능한 행동을 지정할수 있다.
Agent가 학습 Brain에 의해 제어 되면 Agent는 지정된 조치를 수행 할 수 없다.
Agent가 Player또는 경험주의 Brain에 의해 제어 될때 Agent는 계속 마스크 작업을 수행 할것인지 결정할수 있다.
SetActionMask(branch, actionIndices)- 분기는 작업을 마스크하려는 분기의 인덱스 (0에서 시작)입니다.
- actionIndices는 에이전트가 수행 할 수없는 작업 인덱스에 해당하는 int 또는 단일 int의 목록입니다.
예를들어 2개의 분가가 있는 Agent가 있고 첫번째 분기에 4개의 가능한 조치가 있다고 하자
: 아무것도하지 말라", "뛰어 오르다", "쏴라", "무기 변경하기"
그런 다음 에이전트는 다음 결정을 위해 "아무것도하지 않거나"무기를 변경합니다 (조치 색인 1과 2는 가려져 있기 때문에)
SetActionMask(0, new int[2]{1,2})
- 여러 분기에 마스크를 넣으려면 SetActionMask를 여러 번 호출 할 수 있습니다.
- 가지의 모든 행동을 숨길 수는 없습니다.
- 연속 제어에서 동작을 마스킹 할 수 없습니다.
Rewards
보강 학습에서 보상은 상담원이 올바르게 수행 한 신호입니다.
Unity-Technologies/ml-agents
Unity Machine Learning Agents Toolkit. Contribute to Unity-Technologies/ml-agents development by creating an account on GitHub.
github.com
'Unity3D > ml-agent' 카테고리의 다른 글
| [ml-agent] Learning-Environment-Create-New (0) | 2019.05.30 |
|---|---|
| [ml-agent] Training config file (0) | 2019.05.30 |
| [ml-agent] Basic Guide (0) | 2019.05.27 |
| [ml-agent] Background: Jupyter Notebooks (0) | 2019.05.27 |
| [ml-agent] Installation (0) | 2019.05.27 |