

[ml-agent] Learning-Environment-Create-New
Unity3D/ml-agent 2019. 5. 30. 17:33https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Create-New.md
이 튜토리얼은 유니티 환경을 만드과정을 안내 합니다.
이 환경은 유니티 엔진을 사용하여 구축된 애플리케이션으로 Agent를 강화 학습 교육하는데 사용할수 있습니다.
이예제에서는 무작위로 배치된 큐브로 롤(움직이는)하는 공을 훈련 합니다.
공은 또한 플랫폼에서 떨어지지 않도록 배웁니다.
Overview
Unity프로젝트에서 ML-Agents 툴킷을 사용하는 과정은 다음과 같습니다.
1. Agent가 살수 있는 환경을 만드세요. 이 환경을 몇가지 객체가 포함된 간단한 물리적 시뮬레이션에서 전체 게임 또는 생태계에 이르기까지 다양할수 있습니다.
2. 아카데미 하위 클래스를 구현하고 환경을 포함하는 Unity 장면의 GameObject에 추가하십시오.
Academy는 임의의 Agent와 독립적으로 장면을 업데이트하는 몇 가지 옵션 방법을 구현할 수 있습니다.
예를 들어, 환경에서 에이전트 및 기타 항목을 추가, 이동 또는 삭제할 수 있습니다.
3. Assets> Create> ML-Agents> Brain을 클릭하여 하나 이상의 Brain 자산을 생성하고 적절하게 이름을 지정하십시오.
4. Agent의 서브클래스를 작성하세요.
에이전트 하위 클래스는 에이전트가 환경을 관찰하고 할당 된 작업을 수행하며 강화 훈련에 사용 된 보상을 계산하는 데 사용되는 코드를 정의합니다.
또한 에이전트가 작업을 마쳤거나 실패 할 때 옵션 메소드를 구현하여 에이전트를 재설정 할 수 있습니다
5. 적절한 GameObjects, 일반적으로 시뮬레이션에서 에이전트를 나타내는 장면의 오브젝트에 에이전트 서브 클래스를 추가하십시오.
각 Agent 객체에는 Brain 객체가 할당되어야합니다.
6. 교육을받는 경우 아카데미의 BroadcastHub에서 Control 확인란을 선택하십시오.run the training process.
개발환경 셋팅이 안되었다면 아래 링크로 가서 셋팅 하세요.
If you haven't already, follow the installation instructions.
Set Up the Unity Project
1. 달성 할 첫 번째 작업은 새로운 Unity 프로젝트를 만들고 ML-Agents 에셋을 임포트하는 것입니다.
2. Unity Editor를 시작하고 "RollerBall"이라는 새 프로젝트를 만듭니다.
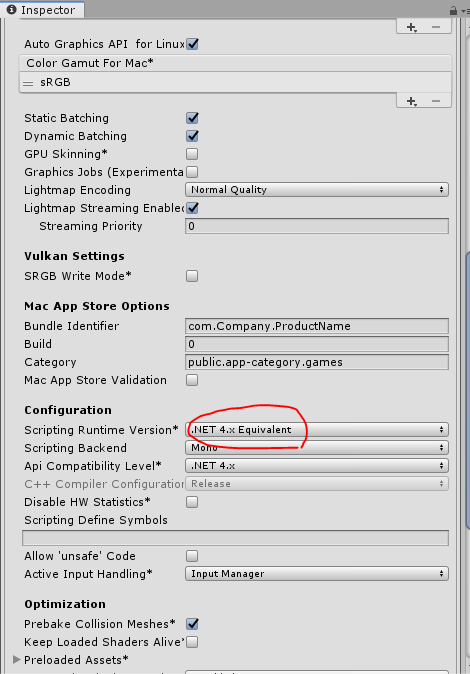
프로젝트의 Scripting Runtime Version이 .NET 4.x Equivalent를 사용하도록 설정되어 있는지 확인하십시오 (이는 Unity 2017의 실험적인 옵션이지만 2018.3의 기본값 임).
File > Build Settings > Player Settings
3. 파일 시스템 창에서 복제 된 ML-Agents 저장소가있는 폴더로 이동합니다.
4. ML-Agents와 Gizmos 폴더를 UnitySDK / Assets에서 Unity Editor Project 창으로 드래그하십시오.
유니티 프로젝트 윈도우는 다음과 같은 애셋을 포함해야합니다 :
Create the Environment
다음으로 우리는 ML-Agents 환경으로 작동 할 수있는 매우 간단한 장면을 만듭니다.
환경의 "물리적"구성 요소에는 에이전트가 이동하기위한 바닥, 에이전트가 탐색 할 목표 또는 대상 역할을하는 큐브 및 에이전트 자체를 나타내는 Sphere가 있습니다.
Create the Floor Plane
1. Hierarchy 창에서 마우스 오른쪽 버튼을 클릭하고 3D Object> Plane을 선택하십시오.
2. GameObject "Floor"의 이름을 지정하십시오.
3. Floor을 선택하면 속성 윈도우에서 속성을 볼 수 있습니다.
4. Transform을 Position = (0, 0, 0), Rotation = (0, 0, 0), Scale = (1, 1, 1)로 설정하십시오.
5. Plane의 Mesh Renderer에서 Materials 속성을 확장하고 기본 재질을 LightGridFloorSquare (또는 원하는 임의의 적합한 재질)로 변경합니다.
(새 재질을 설정하려면 현재 재질 이름 옆의 작은 원 모양 아이콘을 클릭합니다. 개체 선택 대화 상자가 열리므로 현재 프로젝트에있는 모든 재료 목록에서 다른 재료를 선택할 수 있습니다.)
Add the Target Cube
1. Hierarchy 창에서 마우스 오른쪽 버튼을 클릭하고 3D Object> Cube를 선택합니다.
2. GameObject의 이름을 "Target"이라고 지정한다.
3. Cube를 선택하고 인스펙터 창을 본다.
4. Transform을 Position = (3, 0.5, 3), Rotation = (0, 0, 0), Scale = (1, 1, 1)로 설정하십시오.
5. 큐브의 Mesh Renderer에서 Materials 속성을 확장하고 default-material을 Block으로 변경합니다.
Add the Agent Sphere
1. Hierarchy 창에서 마우스 오른쪽 버튼을 클릭하고 3D Object> Sphere를 선택하십시오.
2. GameObject의 이름을 "RollerAgent"로 설정
3. RollerAgent를 선택한후 인스펙터창 보기
4. Transform을 Position = (0, 0.5, 0), Rotation = (0, 0, 0), Scale = (1, 1, 1)로 설정하십시오.
5. Sphere의 Mesh Renderer에서 Materials 속성을 확장하고 Default-Material을 CheckerSquare로 변경합니다.
6. Add Component를 누른다.
7. Physics / Rigidbody 구성 요소를 Sphere에 추가하십시오.
튜토리얼의 뒷부분에서이 GameObject에 컴포넌트로 추가 할 Agent 서브 클래스를 생성합니다.
Add an Empty GameObject to Hold the Academy
1. Hierarchy 창에서 마우스 오른쪽 버튼을 클릭하고 Create Empty를 선택하십시오.
2. GameObject이름을 "Academy"로 설정
런타임에 장면을 더 잘 볼 수 있도록 카메라 각도를 조정할 수 있습니다. 다음 단계는 ML-Agent 구성 요소를 생성하고 추가하는 것입니다.
Implement an Academy
Academy 객체는 장면의 ML-Agents를 조정하고 시뮬레이션 루프의 의사 결정 부분을 유도합니다.
모든 ML-Agent 씬은 하나의 아카데미 인스턴스를 필요로합니다.
기본 아카데미 클래스는 추상 클래스이므로 특정 환경에 대해 메서드를 사용할 필요가 없더라도 사용자 고유의 하위 클래스를 만들어야합니다.
먼저, 앞서 만든 아카데미 GameObject에 새 스크립트 구성 요소를 추가합니다.
1. Inspector 창에서 아카데미 GameObject를 보려면 아카데미 GameObject를 선택하십시오.
2. Add Component버튼을 누른다.
3. 컴포넌트 리스트에서 새로운 스크립트를 선택 한다.
4. 스크립트 이름은 RollerAcademy이다.
5. 생성하고 추가 한다.
다음으로 새로운 RollerAcademy 스크립트를 편집하십시오.
1. Unity Project 창에서 RollerAcademy 스크립트를 두 번 클릭하여 코드 편집기에서 엽니 다. (기본적으로 새 스크립트는 Assets 폴더에 직접 배치됩니다.)
2. 코드 편집기에서 MLAgents;를 사용하여 문을 추가합니다.
3. 기본 클래스를 MonoBehaviour에서 Academy로 변경합니다.
4. 기본적으로 추가 된 Start () 및 Update () 메서드를 삭제합니다.
이러한 기본 장면에서 우리는 아카데미를 초기화, 재설정 또는 환경 내의 객체를 제어 할 필요가 없으므로 가능한 가장 간단한 아카데미 구현을 갖게됩니다.
아카데미 속성의 기본 설정은이 환경에서도 좋습니다. 따라서 Inspector 창에서 RollerAcademy 구성 요소를 변경할 필요가 없습니다.
Broadcast Hub에 RollerBrain을 아직 설치하지 않았을 수도 있습니다.
Add Brain Assets
Brain 객체는 의사 결정 프로세스를 캡슐화합니다.
에이전트는 뇌에 관찰을 보내고 결과에 대한 결정을 기대합니다.
Brain (Learning, Heuristic 또는 Player) 유형은 뇌가 결정을 내리는 방식을 결정합니다. 두뇌를 창조하려면 :
1. Assets> Create> ML-Agents로 이동하여 생성하려는 Brain 에셋의 유형을 선택하십시오. 이 튜토리얼에서는 Learning Brain과 Player Brain을 작성하십시오
RollerBallBrain과 RollerBallPlayer의 이름을 각각 지정하십시오.
나중에 Brain 속성으로 돌아갈 것이지만 RollerBallBrain의 Model 속성은 None으로 두십시오.
Learning Brain에 추가하기 전에 먼저 모델을 훈련시켜야합니다.
Implement an Agent
에이전트를 생성하려면 다음과 같이하십시오.
1. Inspector 창에서 보려면 RollerAgent GameObject를 선택하십시오.
2. 구성 요소 추가를 클릭하십시오.
3. 스크립트 이름을 RollerAgent라고 설정 합니다.
5. 생성하고 추가 하세요.
그런 다음 새 RollerAgent 스크립트를 편집합니다.
1. Unity Project 창에서 RollerAgent 스크립트를 두 번 클릭하여 코드 편집기에서 엽니 다.
2. 편집기에서 MLAgents를 추가합니다. 기본 클래스를 MonoBehaviour에서 Agent로 변경하십시오.
3. Update () 메서드를 삭제하지만 Start () 함수를 사용하므로 지금 당장 그대로 두십시오.
지금까지는 Unity 프로젝트에 ML-Agents를 추가하기 위해 사용하는 기본 단계입니다.
다음으로, 에이전트가 보강 학습을 사용하여 큐브에 롤백하는 법을 배울 수있는 논리를 추가합니다
이 간단한 시나리오에서 우리는 아카데미 객체를 사용하여 환경을 제어하지 않습니다.
예를 들어 시뮬레이션 전이나 시뮬레이션 중에 바닥의 크기를 변경하거나 에이전트 나 다른 객체를 추가 또는 제거하는 등 환경을 변경하려는 경우 아카데미에서 적절한 방법을 구현할 수 있습니다.
대신, 우리는 에이전트가 성공하거나 실패 할 때 자신과 대상을 다시 설정하는 모든 작업을 수행하게 할 것입니다
Initialization and Resetting the Agent
에이전트가 목표에 도달하면 에이전트는 완료되었음을 표시하고 에이전트 재설정 기능은 대상을 임의의 위치로 이동시킵니다.
또한 에이전트가 플랫폼에서 벗어나면 재설정 기능을 통해 플랫폼에 다시 넣습니다.
대상 GameObject를 이동하려면 Transform (3D 세계에서 GameObject의 위치, 방향 및 축척을 저장함)에 대한 참조가 필요합니다.
이 참조를 얻으려면 Transform 유형의 공용 필드를 RollerAgent 클래스에 추가하십시오.
Unity의 구성 요소 공개 필드는 Inspector 창에 표시되므로 Unity Editor에서 대상으로 사용할 GameObject를 선택할 수 있습니다.
에이전트의 속도를 재설정하려면 (나중에 에이전트 강제 이동을 적용하려면) Rigidbody 구성 요소에 대한 참조가 필요합니다. 리지드 바디
리지드 바디 (Rigidbody)는 물리학 시뮬레이션을위한 Unity의 주요 요소입니다. Unity 물리학의 전체 문서는 물리학을 참조하십시오.
Rigidbody 구성 요소가 에이전트 스크립트와 동일한 GameObject에 있기 때문에이 참조를 얻는 가장 좋은 방법은 GameObject.GetComponent <T> ()를 사용하는 것입니다.이 스크립트는 스크립트의 Start () 메소드에서 호출 할 수 있습니다.
지금까지 RollerAgent 스크립트는 다음과 같습니다.
다음으로 Agent.CollectObservations () 메소드를 구현해 보겠습니다.
Observing the Environment
에이전트는 우리가 수집 한 정보를 두뇌에 보내고,이 정보를 사용하여 결정을 내립니다.
에이전트를 훈련 시키거나 (훈련 된 모델을 사용할 때), 데이터는 특징 벡터로서 신경망에 공급됩니다.
에이전트가 작업을 성공적으로 배우려면 정확한 정보를 제공해야합니다.
수집 할 정보를 결정하는 좋은 방법은 문제에 대한 분석 솔루션을 계산하는 데 필요한 것이 무엇인지 고려하는 것입니다.
우리의 경우 에이전트가 수집하는 정보에는 다음이 포함됩니다.
- 타겟의 위치
AddVectorObs(Target.position);
- Agent 자신의 위치
AddVectorObs(this.transform.position);
- 에이전트 속도. 이렇게하면 에이전트가 속도를 제어하여 타겟을 오버 슛하고 플랫폼에서 벗어날 수 있습니다.
// Agent velocity
AddVectorObs(rBody.velocity.x);
AddVectorObs(rBody.velocity.z);
총계로, 상태 관측은 8 개의 가치를 포함하고 우리는 두뇌 재산을 놓기 위하여 주변에 얻을 때 연속적인 국가 공간을 이용할 필요가있다 :
public override void CollectObservations()
{
// Target and Agent positions
AddVectorObs(Target.position);
AddVectorObs(this.transform.position);
// Agent velocity
AddVectorObs(rBody.velocity.x);
AddVectorObs(rBody.velocity.z);
}
에이전트 코드의 마지막 부분은 Agent.AgentAction () 메서드입니다.이 메서드는 Brain에서 결정을 받고 보상을 할당합니다.
Actions
Brain의 결정은 AgentAction () 함수에 전달 된 액션 배열의 형태로 이루어집니다.
이 배열의 요소 수는 상담원의 Brain의 Vector Action Space Type 및 Space Size 설정에 의해 결정됩니다.
RollerAgent는 연속 벡터 작업 공간을 사용하며 두뇌에서 두 개의 연속 제어 신호가 필요합니다.
따라서 Brain Space Size를 2로 설정합니다. 첫 번째 요소 인 action [0]은 x 축을 따라 적용되는 힘을 결정합니다. 액션 [1]은 z 축을 따라 적용되는 힘을 결정합니다.
(상담원이 3 차원으로 이동하도록 허용 한 경우 벡터 작업 크기를 3으로 설정해야합니다.)
Brain은 액션 배열의 값이 무엇을 의미하는지 실제로 알지 못합니다.
교육 프로세스는 관찰 입력에 대한 응답으로 동작 값을 조정 한 다음 결과로 얻는 보상의 종류를 확인합니다.
RollerAgent는 Rigidbody.AddForce 함수를 사용하여 action [] 배열의 값을 Rigidbody 구성 요소 인 rBody에 적용합니다.
Vector3 controlSignal = Vector3.zero;
controlSignal.x = action[0];
controlSignal.z = action[1];
rBody.AddForce(controlSignal * speed);
Rewards
강화 학습에는 보상이 필요합니다.
AgentAction () 함수에서 보상을 할당하십시오. 학습 알고리즘은 시뮬레이션 및 학습 과정에서 상담원에게 할당 된 보상을 사용하여 상담원에게 최적의 작업을 제공하는지 여부를 결정합니다.
할당 된 작업을 완료하기 위해 상담원에게 보상하기를 원합니다.
이 경우 에이전트는 대상 큐브에 도달하기 위해 1.0의 보상을받습니다.
float distanceToTarget = Vector3.Distance(this.transform.position,
Target.position);
// Reached target
if (distanceToTarget < 1.42f)
{
SetReward(1.0f);
Done();
}
참고 : 상담원을 완료로 표시하면 재설정 될 때까지 해당 상담원이 활동을 중지합니다.
관리자에서 Agent.ResetOnDone 속성을 true로 설정하여 에이전트를 즉시 재설정하거나 아카데미에서 환경을 재설정 할 때까지 기다릴 수 있습니다
그의 RollerBall 환경은 ResetOnDone 메커니즘에 의존하며 아카데미의 최대 단계 제한을 설정하지 않기 때문에 환경을 재설정하지 않습니다.
마지막으로, 에이전트가 플랫폼에서 떨어지면 에이전트 자체를 재설정 할 수 있도록 에이전트를 완료로 설정하십시오.
// Fell off platform
if (this.transform.position.y < 0)
{
Done();
}
AgentAction()
위에 요약 된 조치 및 보상 논리로 AgentAction () 함수의 최종 버전은 다음과 같습니다.
함수 앞에 정의 된 속도 클래스 변수에 주목하십시오. 속도는 공개되어 있으므로 관리자 창에서 값을 설정할 수 있습니다.
Final Editor Setup
이제 GameObjects와 ML-Agent 구성 요소가 모두 갖추어 졌으므로 Unity Editor에서 모든 것을 하나로 연결해야합니다.
여기에는 Brain 자산을 Agent에 할당하고, Agent 구성 요소의 일부 속성을 변경하고, Brain 속성을 Agent 코드와 호환되도록 설정합니다.
1. Academy Inspector에서 RollerBallBrain 및 RollerBallPlayer Brains를 Broadcast Hub에 추가하십시오.
2. Inspector 창에서 해당 속성을 표시하려면 RollerAgent GameObject를 선택하십시오.
3. Brain RollerBallPlayer를 프로젝트 창에서 RollerAgent Brain 필드로 드래그하십시오.
4. 결정 간격을 1에서 10으로 변경하십시오.
5. Hierarchy 창에서 RollerAgent Target 필드로 대상 GameObject를 드래그하십시오.
마지막으로 Inspector 창에서 해당 속성을 볼 수 있도록 Project 윈도우에서 RollerBallBrain Asset을 선택하십시오. 다음 속성을 설정합니다.
- Vector Observation Space Size = 8
- Vector Action Space Type = Continuous
- Vector Action Space Size = 2
Project 창에서 RollerBallPlayer Asset을 선택하고 동일한 속성 값을 설정하십시오.
이제 교육을 받기 전에 환경을 테스트 할 준비가되었습니다.
Testing the Environment
확장 된 교육을 시작하기 전에 수동으로 환경을 테스트하는 것이 좋습니다.
우리가 RollerBallPlayer Brain을 만든 이유는 바로 키보드 컨트롤을 사용하여 Agent를 제어 할 수 있기 때문입니다.
하지만 먼저 키보드 대 액션 매핑을 정의해야합니다.
RollerAgent는 Action Size가 2 임에도 불구하고 양수 값을 지정하는 데 하나의 키를 사용하고 총 네 개의 키에 대해 각 동작에 대해 음수 값을 지정하기 위해 하나의 키를 사용합니다.
1. Inspector에서 속성을 보려면 RollerBallPlayer Asset을 선택하십시오.
2. 키 연속 플레이어 동작 사전을 확장합니다 (PlayerBrain을 사용할 때만 표시됨).
3. Size 를 4로 설정
4. 다음 맵핑을 설정하십시오.
ElementKeyIndexValue
| Element 0 | D | 0 | 1 |
| Element 1 | A | 0 | -1 |
| Element 2 | W | 1 | 1 |
| Element 3 | S | 1 | -1 |
Index 값은 AgentAction () 함수에 전달 된 액션 배열의 인덱스에 해당합니다. 키를 누를 때 값은 [인덱스] 동작에 할당됩니다.
Play를 눌러 장면을 실행하고 WASD 키를 사용하여 플랫폼에서 에이전트를 이동하십시오.
유니티 편집기 콘솔 창에 오류가 표시되지 않았는지, 에이전트가 대상에 도달하거나 플랫폼에서 떨어질 때 에이전트가 재설정되는지 확인하십시오.
보다 복잡한 디버깅을 위해 ML-Agents SDK에는 게임 윈도우에 에이전트 상태 정보를 쉽게 표시하는 데 사용할 수있는 편리한 Monitor 클래스가 포함되어 있습니다.
수행 할 수있는 추가 테스트 중 하나는 먼저 notebooks / getting-started.ipynb Jupyter 노트북을 사용하여 환경 및 Python API가 예상대로 작동하는지 확인하는 것입니다.
노트북에서 env_name을이 환경을 빌드 할 때 지정한 환경 파일의 이름으로 설정하십시오.
Training the Environment
이제 요원을 훈련시킬 수 있습니다. 훈련 준비를하려면 먼저 에이전트의 Brain을 Learning Brain RollerBallBrain으로 변경해야합니다.
그런 다음 Academy GameObject를 선택하고 Broadcast Hub 목록에서 RollerBallBrain 항목에 대한 Control 확인란을 선택하십시오. 이 과정은 Training ML-Agents에서 설명한 것과 같습니다.
교육용 하이퍼 매개 변수는 mlagents-learn 프로그램에 전달한 구성 파일에 지정되어 있습니다.
config / trainer_config.yaml 파일 (ml-agents 폴더에 있음)에 지정된 기본 설정을 사용하여 RollerAgent는 훈련에 약 30 만 단계가 소요됩니다.
D:\workspace\unity\git\ml-agents\config
그러나 다음 하이퍼 매개 변수를 변경하여 교육 속도를 상당히 높일 수 있습니다 (20,000 단계 미만).
batch_size: 10
buffer_size: 100이 예제는 입력 및 출력이 적은 매우 간단한 교육 환경을 생성하므로 작은 배치 및 버퍼 크기를 사용하면 교육 속도가 상당히 빨라집니다.
그러나 환경을 더 복잡하게하거나 보상이나 관측 기능을 변경하면 다른 하이퍼 매개 변수 값으로 더 나은 학습을 할 수 있습니다.
참고 : 상담원의 DecisionFrequency 매개 변수는 이러한 하이퍼 매개 변수 값을 설정하는 것 외에도 교육 시간 및 성공에 큰 효과가 있습니다.
값이 클수록 교육 알고리즘이 고려해야하는 의사 결정 횟수가 줄어들며이 간단한 환경에서 교육 속도가 빨라집니다.
편집기에서 트레이닝하려면, 재생을 누르기 전에 터미널 또는 콘솔 창에서 다음의 Python 명령을 실행하십시오 :
mlagents-learn config/config.yaml --run-id=RollerBall-1 --train여기서 config.yaml은 뇌의 batch_size 및 buffer_size 하이퍼 매개 변수를 변경하기 위해 편집 한 trainer_config.yaml의 복사본입니다.
수정
'Unity3D > ml-agent' 카테고리의 다른 글
| How do I train brain after building mobile with ml-agent? (0) | 2019.06.02 |
|---|---|
| Running "mlagents-learn" from Unity Process (0) | 2019.06.01 |
| [ml-agent] Training config file (0) | 2019.05.30 |
| [ml-agent] Agents (0) | 2019.05.28 |
| [ml-agent] Basic Guide (0) | 2019.05.27 |